Introduction
Motivation
Lane Detection is one of the most important and preliminary tasks of autonomous driving. Good lane detection can lead to better automation and enhanced driving experience. If lane detection is not done properly, there can be adverse effects in autonomous driving which may even lead to accidents. Therefore, the performance of a lane detection system is crucial even in adverse visibility conditions such as bad lighting, glare, rain, snow, etc. Lane detection problem has been tackled through various research efforts, but robust lane detection in adverse visibility conditions is still a challenge.
Adverse Visibility Conditions:
Some visibility conditions are not very favourable to perform the task of lane detection. Current lane detection approaches work well in well lit scenarios with good lane markings visible. But some adverse visibility conditions such as presence of shadows, night, snow, rain may deteriorate the performance of a lane detection system and lane detection becomes more challenging.
Some of the example images with adverse visibility conditions are shown below:
 |
 |
|---|---|
| Glaze | Curved Lanes |
 |
 |
|---|---|
| No Lanes | Night |
What happens to lane detection in adverse conditions?
In the pictures below, we can see that how state of the art models fail miserably at a common adverse condition. We can see that in the first picture, the lane markings are almost flawless, but as soon as we look at a curved lane, which is one of the adverse conditions, we see that none of the lanes where detected. This can lead to serious miscalculations and even accidents when it comes to lane detecction for self driving cars.
 |
 |
|---|---|
| Normal Condition | Adverse Condition |
Hence we can conclude that there is a sharp dip in accuracy in lane detection in adverse conditions. To validate this hypothesis, we have shown the accuracy results of various conditions in the next section.
Spatial Convolutional Neural Network:
The current state of the art and our baseline model for lane detection was SCNN - Spatial CNN. CNN’s are heavily deployed for various image tasks like classification, segmentations, instance segmentation, image captioning. But when it comes to videos, CNNs are not able to effectively capture the temporal information that spans accross multiple frames. CNNs extract semantics only from raw pixels and hence miss out on capturing the spatial relationships of pixels.
This is where SCNN steps in. Objects like lanes, poles and street markings have a common shape accross their instances. They have a strong shape bias that can be learned by a CNN model. SCNNs can learn spatial relationships like strong shape priors of lane markings. It generalizes the deep layer-by-layer convolutions to slice-by-slice convolutions and hence enables message passing between pixels across rows and columns in a layer.
Traditional methods to model spatial relationship are based on Markov Random Fields. For MRF, the large convolution kernel is hard to learn and initialize. Additionally, MRF applied to the output of CNN, while the top hidden layer, which comprises richer information, might be a better place to model spatial relationship. To address these issues, Pan et al. have presented the Spatial CNN. The the below figure, part (a) shows a MRF based CNN and figure (b) shows the Spatial CNN propsed by Pan et al.
 |
|---|
| SCNN vs MRF |
Below we show the results of applying VGG-16 training model on various driving video frames. We can see that SCNN with VGG-16, together is able to caputre the minute nuances while detecting lanes and is able to detect lanes very well. The results obtained on VGG-16 with SCNN is much closer to the ground truth than just by VGG-16.
 |
|---|
| SCNN |
CULane Dataset:
The achieve the above results, the training was performed on the CULane Dataset. It is a large scale dataset for lane detection that was developed at the Chinese Univesity of Hong Kong. It is the first dataset with labels for multiple challenging and adverse scenarios.
Some of the major properties of CULane are :
- 55 hours of videos with 133,235 frames
- 88880 frames for training set
- 9675 frames for validation set
- 34680 frames for test set
In the below, we show the distribution of the CULane dataset accross various scenarios like normal, night, curved lane, glaze, etc.
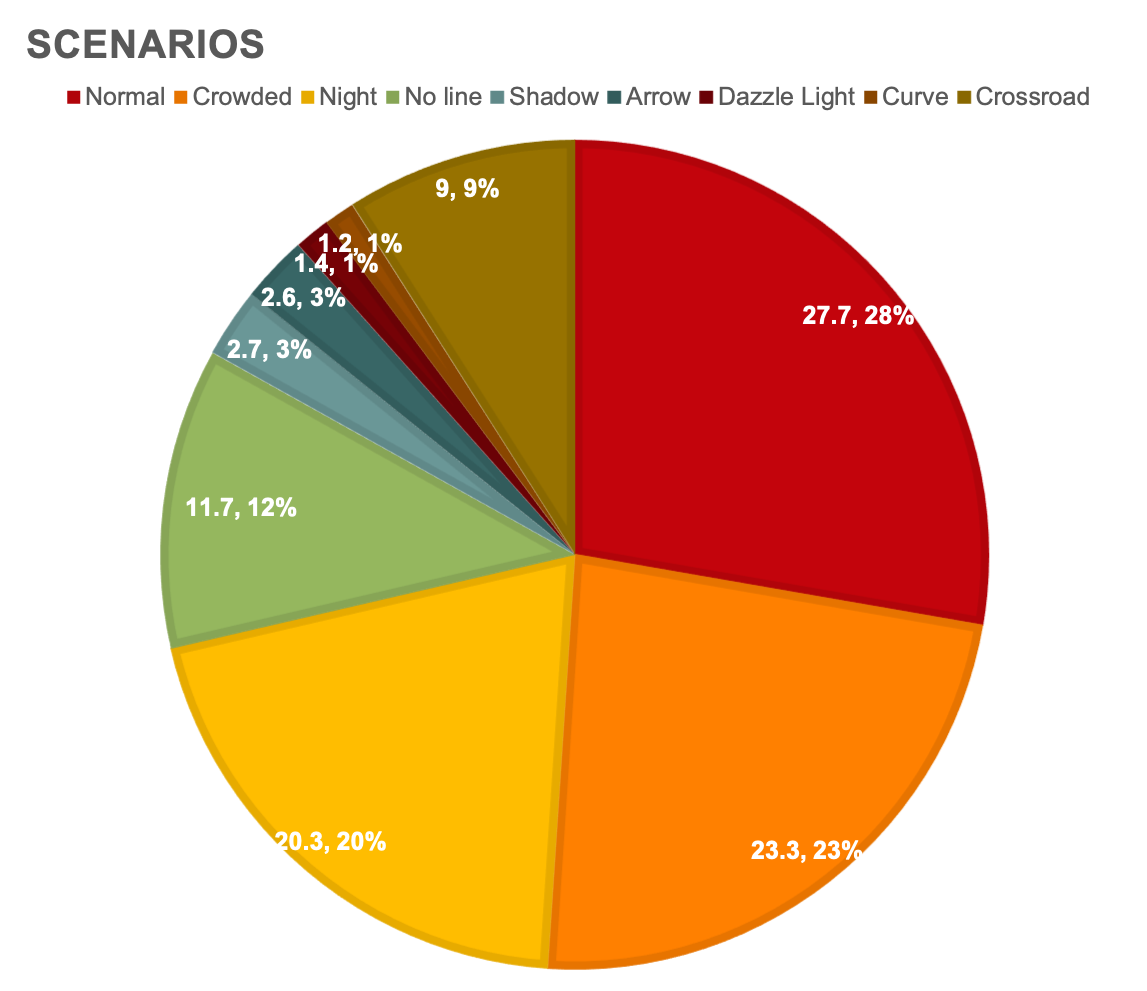
CULane Dataset - Various Categories
The figure below shows the labled markings for a small subset of the frames in CULane.

CULane markings
Spatial CNN Results:
In the table below, we can see the F1-measures of lane detection for various conditions. We can see that the model does a really good job on lane detection for various normal conditions. But, if we look at the markings in red text, we can see that the SCNN model does not live up to the expections of performing effective lane detection in adverse conditions. We decided to tackle this problem and improve lane detection for one of the adverse conditions, ie. glaze.
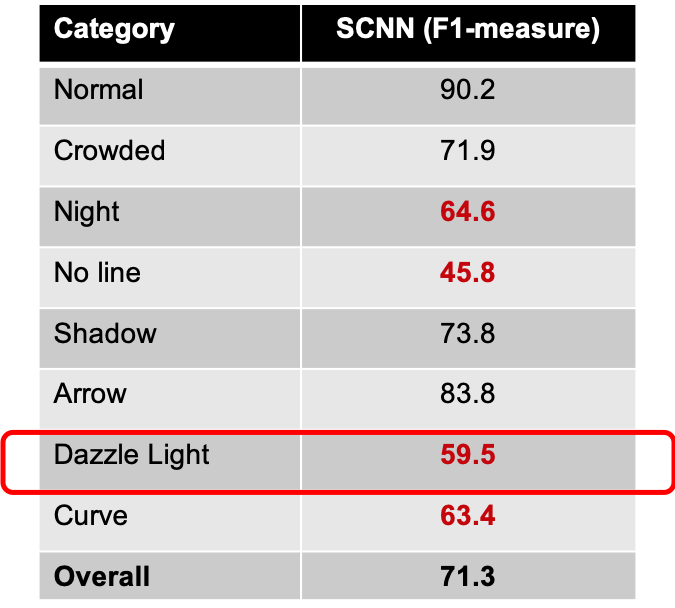
SCNN Results